분산분석이란?
연속형 자료에 대한 2개 이상의 그룹 간의 평균차이를 검정하는것
평균의 차이를 파악하기 위해 변동성을 이용한다. 그룹별 평균이 다르다는 것은 평균들의 변동성이 크다는 사실을 의미한다.
용어 설명
- 요인(factor) : 모집단(그룹)의 구분기준.(나에게는 feature라는 명칭이 조금더 와닿는다)
- 처리(treatment) : 요인을 구성하는 각 모집단(A타입, B타입, C타입)
요인의 개수에 따라 일원분산분석(one-way ANOVA), 이원분산분석(two-way ANOVA) 등으로 구분한다.
일원분산분석(One-way ANOVA)
일원배치 자료의 구조
- 1개의 요인에 대해 k개의 처리(그룹)으로 분류되어있는 자료
- 각 처리(그룹)마다의 표본수가 달라도 됨.
일원분산분석의 가정
- 정규성
- 등분산성
- 독립성
통계적 가설
- 귀무가설 : 집단간 평균의 차이가 없다
- 대립가설 : 집단간 평균의 차이가 존재한다
- 한쌍만 달라도 다른것을 의미한다.
분석에 사용되는 3가지 종류의 제곱합
총 제곱합(SST : Sum of Squares of Total)
그룹에 무관한 전체자료의 변동성을 측정

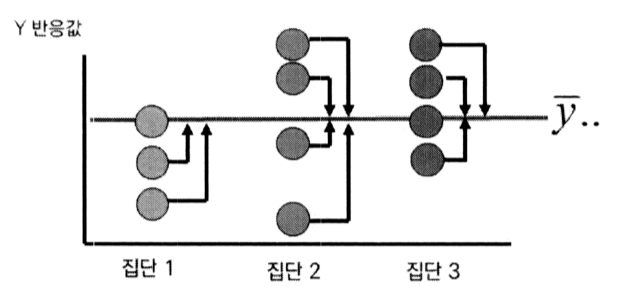
처리제곱합(SSRT : Sum of Squares of Treatment)
각 그룹별 평균의 변동을 측정


오차제곱합(SSE : Sum of Squares of Error)
각 그룹내에서의 변동을 측정
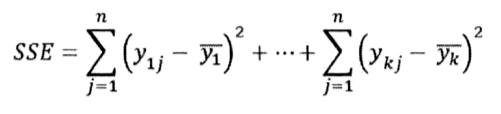

검정통계량
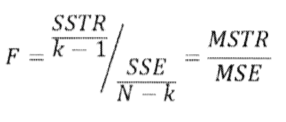
여기서 k-1, N-k는 각각 자유도이다.
* N = 총 관측치수, k = 총 처리(그룹)수
statsmodels.formula.api.ols, statsmodels.stats.anova.anova_lm 두가지 파이썬 함수로 측정가능
등분산 검정(Test of Homogeneity)
One-Way ANOVA 검정의 전제 조건이 정규성, 등분산성, 독립성인데 등분산인지는 어떻게 알 수 있을까?
Bartlett 검정을 통해가능하다.(scipy.stasts.bartlett)
이원분산분석(Two-way ANOVA)
요인이 두개 이상이고 처리(그룹)이 두개 이상인 경우이다.
요인간의 상호작용이 있는지 확인하고, 상호작용이 없을시 일원분산분석을 각각의 요인에 대해 수행한다.
일원분산분석처럼 statsmodels.formula.api.ols, statsmodels.stats.anova.anova_lm을 통해 측정 가능하다
상호작용항을 꼭 명시해야한다. ex) ols(' A ~ B + C + B:C', data=data)
'ML | DL | Big data > Data Science' 카테고리의 다른 글
| 단순/다중 선형회귀 모형 - 유의성 검정 / 적합도 측정 (1) | 2023.03.06 |
|---|---|
| 비모수 검정 - Wilcoxon rank-sum(Mann-Whitney U) / Wilcoxon Signed rank test (0) | 2023.03.02 |
| 범주형 자료 검정 - Chi-Squared Test (0) | 2023.03.02 |
| 정규성 검정 및 변환 (0) | 2023.02.28 |
| 표본/분산 차이에 대한 가설 검정 방법 (0) | 2023.02.28 |
| 통계적 가설 검정 방법 (0) | 2023.02.28 |




댓글