왜도와 첨도의 개념을 정리하려고 했는데, 그전에 좋은 글을 한 가지 발견해서 정리해놓고자 한다.
“Facts are stubborn things, but statistics are pliable.”― Mark Twain
데이터 과학자들의 목표는 표본에 대한 결론을 도출하는 것이 아니라 제공된 샘플에서 모집단에 대한 결론을 도출하는 것이다. 따라서 데이터 과학자들은 표본에 대한 통계를 사용하여 모집단의 값에 대해 유추해야 한다. 모집단의 이러한 값을 모수라고 한다. 모수는 모집단 평균과 중위수와 같이 전체 모집단의 알 수 없는 특성이다. 표본 통계량은 표본으로 추출되는 모집단의 일부 특성을 설명한다. 표본 평균(mean)과 중위수(median)는 고정값이다.
Sampling Error / 표본 오차
예를 들어, 공원에서 아침 산책을 하는 3000명의 사람들이 있다고 가정해보자. 3000명의 평균 몸무게와 키를 알고 싶은데, 우리는 총인구 3000명을 모두 측정할 수 없기에, 일부, 즉 1000명만 측정할 것이다. 만약 표본이 무작위로 선택된다면, 기대 평균은 실제 평균과 유사하다. 그러나 랜덤 표본이기 때문에 평균은 실제 평균과 다를 수 있다. 표본 평균과 참 의미 실제 평균의 차이를 표본오차라고 한다.
Standard Error / 표준 오차
모든 평균의 표준 편차를 말한다. 표본 데이터들의 평균값이 서로 얼마나 다른지 보여준다.
3일 동안 얼마나 많은 판매가 발생하는지 관찰하고 싶다고 가정해 보자. 매일매일의 매출로 평균 매출을 계산할 수도 있다. 하지만 할인, 휴일 등 매출에 영향을 미치는 외부 요인이 많다. 따라서 하루의 평균을 취하는 대신 3일의 평균을 취한다.
평균의 표준 오차(Standard Error)는 관측치가 매번 달라 평균의 변화를 보여준다.
데이터 집합의 여러 표본을 측정하면, 평균은 같지 않고 여러 값이 측정될 것이다. 표본의 SE(Standard Error)는 표본 평균의 표준 편차로, 넓게 흩어진 측정 결과를 보여준다.
Confidence Interval & Confidence Level / 신뢰 구간 & 신뢰 수준
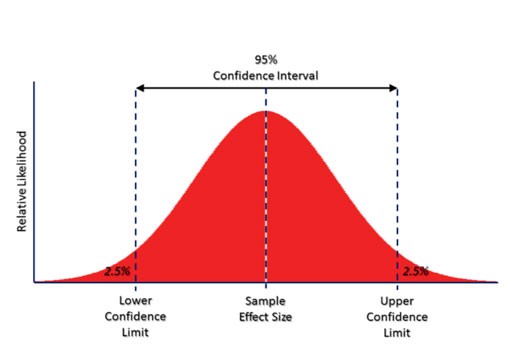
"조사 결과 신뢰도가 96%인 과수원 오렌지의 무게는 (132~139gm) 정도인 것으로 나타났다."
(132–139 gm)은 신뢰 구간이다. 실제로 가치가 있는 값의 범위라는 뜻이다. CI(Confidence Interval)는 모집단이 존재하는 것으로 확신하는 범위를 표현하기 위해 사용된다. 모집단의 추정치를 표현하고 싶을 때마다 CI를 명시하는 것이 좋은 방법이다. CI의 폭은 수집된 표본의 모집단에 대해 가지고 있는 확실성에 대해 많은 것을 말해준다. 모집단에 대해 잘 모를 때는 t-분포를 사용하여 신뢰 구간을 찾아야 한다.
신뢰 수준 96%는 조사나 여론조사가 같은 조건으로 반복적으로 반복될 경우 조사 결과가 실제 인구의 96%와 일치한다는 것을 의미한다.
신뢰 구간(CI)에 영향을 미치는 두 가지 사항은 분산과 표본 사이즈이다.
분산 : 모집단의 모든 값이 비슷하다면 표본의 분산은 매우 작고 표본 관측치는 서로 비슷할 것이다.
- 분산이 작을 경우 샘플이 비슷하고 CI구간이 좁아짐
- 분산이 클 경우 샘플이 다양하고 CI구간이 넓어짐
표본 사이즈 : 적은 수의 표본을 추출하면 추론을 뒷받침 할 만한 결과가 나오지 않는다. 적은 수의 샘플은 서로 다르고, 상세도가 적어 CI 폭이 넓어진다.
- 표본 사이즈가 커지면 세부 정보가 많아지고, CI가 좁아진다.
- 표본 사이즈가 작아지면 세부 정보가 적어지고, CI가 넓어진다.
Margin of Error / 허용 오차
Survey는 전체 인구가 아니라 표본으로부터 수집된 사실에 기반한다. 표본오차와 같이 표본에 근거해서 실제 통계를 추론해야 하기 때문에 어느 정도 오차가 발생하기 마련인데, 이는 모든 모집단이 고려되지 않기 때문이다. 오차 한계는 표본 결과가 실제 모집단의 결과와 다를 것으로 예상되는 최대 양을 측정하도록 되어 있다.
margin of error(허용 오차) = critical value(임계값) * standard error(표준 오차)
예: 우리는 49%가 선거에서 OO에게 투표할 것이며, 허용 오차는 +/-이다. 이 말은 인구의 47%(49%-2%)에서 51%(49%+2%) 사이에서 OO에게 투표할 것이라고 확신한다는 것을 의미한다.
Hypothesis Test / 가설 실험
조사와 여론조사 결과를 테스트해 그 결과가 의미 있고 반복 가능한지 무작위가 아닌지를 점검하는 것이 주요 목적이다. 즉, 통계를 이용해 주장을 받아들일 수 있느냐, 거부할 수 있느냐를 판단하는 것이 목적이다. 표본에 대해 두 가지 주장을 조사한다. 예: 두통약은 효과가 없을까, 아니면 여학생과 남학생의 키가 다를까? 일반적으로 이 문장은 "만약 (독립변수에 대해 이 작업을 수행)하면 (의존 변수에 이 일이 일어날 것)"의 형태로 되어 있다.
Null and Alternative Hypothesis / 귀무가설 및 대립 가설
귀무가설(H0 / null hypothesis)은 일반적으로 표본 관측치가 순전히 우연에서 나온 가설이다. 흔히 알려진 사실이다. 연구원들은 그것을 거부하기 위해 노력한다. 표본오차의 결과에는 관계가 없고 무엇이든지 반영되고 있다는 생각이다. 관측 결과에 통계적 의미가 존재하지 않는다고 제안한다. 분석이나 통계적 절차는 귀무가설 H0이 실제로 거짓일 때 거짓임을 보여주곤 한다.
대립 가설(H1 또는 Ha / alternative hypothesis)은 표본 관측이 일부 비 랜덤 원인에 의해 영향을 받는다는 가설이다. 표본은 모집단의 통계를 반영한다.
예) 귀무가설 : 지구는 평평하다. 대립 가설 : 지구는 둥글다.
Type I and Type II Error / 타입 I 오류와 타입 II 오류
Type I error : 참 귀무가설을 기각하고 대체 가설을 수용하는 것을 의미한다. false positvie이다. 예) 연기가 나지 않지만 연기를 감지했다고 울리는 연기 감지기
Type II error : 참 대체 가설을 기각하고 귀무가설을 받아들이는 것을 의미한다. false negative이다. 예) 화재경보기가 화재를 감지하지 못할 때.
Alpha and Beta Level
alpha level은 α로도 알려져 있다. Type I Error를 범할 확률을 뜻 한다. 귀무가설이 사실일 때 기각할 확률이다. alpha level이 낮아지기 위해서는 귀무가설을 기각할 수 있는 강력한 증거가 필요하다. 1%의 alpha level이 5%보다 더 많은 통계적 증거를 필요로 한다.
왜 5% 수준이 보편적으로 사용될까?
alpha level이 작을수록 참 귀무가설을 기각할 가능성이 낮다. 또한 작은 영역 때문에 거짓 귀무가설을 기각할 수 있는 확률도 낮다. Type I Error를 피하려고 할수록 Type II Error를 범할 가능성이 높아진다.
신뢰 수준은 (1-α)이며, 참인 귀무가설을 받아들이는 것을 의미한다.
beta level은 Type II Error를 범할 확률, 즉, 참인 대체 가설을 기각할 확률을 뜻한다.
P-Value
모든 가설 테스트에 의해 데이터의 형태로 모집단이 제공한 증거의 강도를 확인하는 데 사용된다. 귀무가설과 반대되는 증거다. 0과 1 사이 값이다.
P-Value가 작다(≤0.05)는 뜻은 귀무가설이 거짓이라는 강력한 증거이기에 귀무가설을 기각한다. 표본 결과가 참인 귀무가설과 일치하지 않는다는 뜻이다.
P-Value가 크다(>0.05)는 뜻은 귀무가설이 거짓이라는 증거가 약하므로 귀무가설을 기각하지 않는다. 표본 결과가 참인 귀무가설과 일치 한다는 뜻이다.
P-Value이 alpha level보다 작거나 같으면 귀무가설을 기각한다.
Reference
'ML | DL | Big data > Data Science' 카테고리의 다른 글
| 통계적 가설 검정 방법 (0) | 2023.02.28 |
|---|---|
| 빅데이터 개요 (0) | 2023.02.28 |
| 불균형 클래스 분류(Imbalanced Classification)를 위한 4가지 방법 (2) | 2020.09.04 |
| 누락 데이터(Missing value)를 처리하는 7가지 방법 / Data Imputation (2) | 2020.08.14 |
| 비대칭(skewed) 데이터를 처리하는 3가지 방법 / Skewed Data (2) | 2020.08.13 |
| Skew(왜도) 와 Kurtosis(첨도) - 데이터 과학에서 알아야 할 두가지 중요한 통계 용어 (0) | 2020.08.12 |




댓글