
요즘 현업에서 자주 사용하는 모델 중 하나가 XGBoost이다.
개인적으로 내 업무는 Data Scientist보다 Data Engineer에 가까워서 모델에 관해 심도 깊은 이해는 필요 없지만, 어느 정도의 이해는 필요하다고 생각된다.
그래서 겉핥는 정도의 이론 부분을 포함하여 사용법 예제, 시행착오 등을 순차적으로 포스팅할 예정이다.
사전 필요 지식
XGBoost 학습을 위해서는 다음에 관한 지식이 필요하다. 추후 기회가 되면 포스팅 할 예정.
- Gradient Boost
- Regression
- Regularization
XGBoost란?
[XGBoost: A Scalable Tree Boosting System] 논문에서 소개된 "Extreme Gradient Boosting"을 의미하며, 여기서 "Gradient Boosting"이라는 용어는 [Greedy Function Approximation: A Gradient Boosting Machine, by Friedman] 논문에서 처음 나왔다. XGBoost는 Gradient Boosting 방법 중 한 가지이다.
XGBoost는 어원처럼 처럼 Extreme 하다.
많은 머신러닝 방법 중에 하나인데 Decision tree를 기반으로 한 Ensemble 방법. 그중에서도 Boosting을 기반으로 하는 머신러닝 방법이다.
효율성과 유연성, 휴대성(efficient, flexible, portable)이 뛰어나도록 최적화된 distributed gradient boosting 라이브러리로도 제공된다. Gradient Boosting framework 아래 머신러닝 알고리즘을 구현한다. XGBoost는 많은 데이터 과학 문제를 빠르고 정확하게 해결하는 parallel tree boosting(GBDT, GBM이라고도 함)을 제공한다. 동일한 코드가 주요 분산 환경(하둡, SGE, MPI)에서 실행되며 수십억 가지의 문제를 해결할 수 있다.
왜 XGBoost를 쓸까?
- 설명에서 처럼 효율성과 유연성, 휴대성(efficient, flexible, portable)이 뛰어나다.
(라고 공홈에 써져있다.) - 유연한 Learning 시스템 - 여러 파라미터를 조절해가면서 최적의 Model을 만들 수 있음.
- Over fitting(과적합)을 방지할 수 있다.
- 신경망에 비해 시각화가 쉽고, 이해하기보다 직관적이다.
- 자원(CPU, 메모리)이 많으면 많을수록 빠르게 학습하고 예측할 수 있다.
- Cross validation을 지원한다.
- 높은 성능을 나타낸다. 이 부분이 현업에서 뛰면서 가장 크게 와 닿은 부분이다. 대부분의 데이터 셋에서 90%의 이상이 GBM보다 더 높은 성능을 보여주었다. 또한, 실제로 Kaggle에서 XGBoost를 쓴 결과들이 상위권을 쓸어 담기 시작하면서 사람들이 너도 나도 사용하기 시작했다.
- C언어로 작성했기에 수행 속도가 빠르다.
(라고 하는데 엄청난 체감은 안된다.. 뭐 딥러닝 보다야 빠르겠지..)
어떻게 학습되나?
* 주의
XGBoost 모델을 만드는 방법은 매우 다양한데, 여기에서는 가장 보편적인 방법으로 설명한다. 또한 Regression을 예로든다. Classification 도 거의 비슷한 방법으로 학습되니 ‘이러한 느낌으로 학습된다.’고 이해하면 될 것 같다.

위와 같은 데이터가 있다고 가정하자. X축은 복용량이고, Y축은 효과이다.
즉, 빨간색은 별로 효과를 보지 못한 경우, 파란색은 효과가 나타난 경우이다.
이런 슈퍼 심플한 데이터셋을 통해 복용량에 따른 효과 정도를 예측하는 모델을 만들어보자.

초기 예측값은 따로 설정하지 않으면 0.5로 초기화된다. 검은색 진한 줄로 표시되어 있다.
(즉, 복용량이 어떻든 효과가 0.5라고 결론 내는 하나의 decision tree인 샘이다.
왜 0.5일까 생각해봤는데, 0과 1로 예측하는 경우가 많아서 그 중간 값인 0.5를 base_score로 주는 것 같다.)
이 단일 예측을 트리 구조처럼 여러 예측값으로 나눠야 한다.. 어떻게? Gain을 가장 극대화하는 방법으로.
Gain을 계산 법은 다음과 같고

Similarity Score를 계산하는 방법은 다음과 같다.

여기에서는 λ을 0이라고 생각하고 무시해도 좋다. Overfitting을 다루기 위한 정규화 파라미터이다.
다음 포스팅에서 다룰 예정.
이 케이스에서 Old Similarity Score는 다음과 같이 계산된다.

이제 New Simlarity Score를 계산해보자.

트리의 분기 조건을 각각 빨간 줄, 초록 줄, 파란 줄로 설정하고 나누어 보았을 때의 New Similarity Score를 계산한다.
총 유사도(Similarity Score)는 모든 리프 노드의 유사도의 합이다.
예를 들어, 이 예제에서 빨간 줄로 나눴을 때의 총유사도는 다음과 같이 110.25 + 14.08 이 되겠다.

그리고 Gain값은 (110.25 +14.08) – 4 가 되겠다.
빨간, 초록, 파랑으로 각각 나누어보고 Gain 값이 가장 높은 쪽으로 분기한다.
여기에서는 빨강으로 나누었을 때 Gain 값이 가장 높으므로 아래와 같이 분기한다.
(포스팅에선 귀찮으므로 초록과 파랑은 계산 생략)

빨간색을 기준으로 분기한 Tree를 만들고 리프 노드(Leaf node)에 대해서 위 작업을 재귀적으로 반복한다.
만약 모든 조건에서 Gain값이 음수일 경우 분기를 중지한다. 이 예제에서는 위와 같이 완성된다.
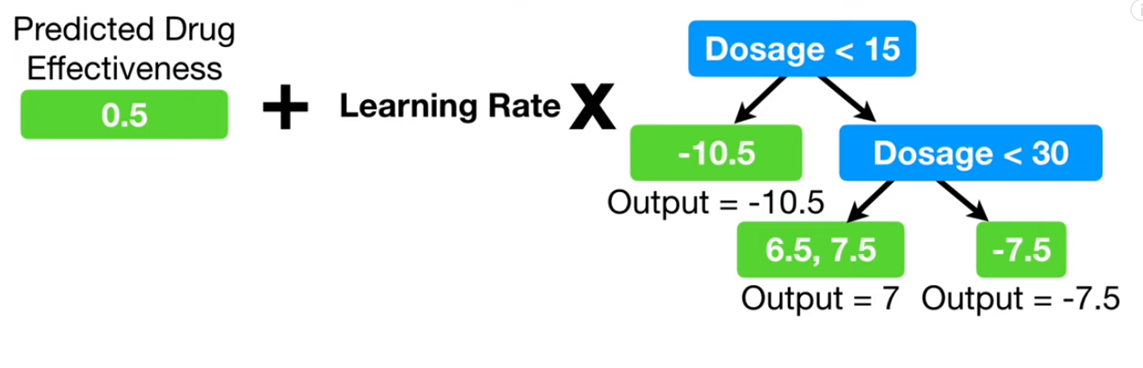
이후 각각의 예측값을 위의 식으로 변경한 트리를 완성한다. 학습률(Learning Rate)은 모델에 따라 다르게 지정하며 라이브러리에서는 eta로 표기된다.
지금까지의 과정을 통해 새로 만들어진 Tree에 대해서 반복한다. N회 반복하거나 M회 이상 validation 결과가 개선되지 않을 때 종료한다. (N과 M은 개발자가 지정한다.)

이 예제에서는 순차적으로 위와 같이 변화한다.
이렇게 만들어진 모든 트리마다 각각의 weight를 갖고 부스팅 방식으로 최종 output을 결정한다.
Reference
- XGBoost Documentation
- StatQuest with Josh Starmer 유튜브 강의
- XGBoost: A Scalable Tree Boosting System 논문
'ML | DL | Big data > ML' 카테고리의 다른 글
| VAR(Vector Auto Regression)을 이용한 다변량 시계열 분석 및 예측 (6) | 2020.09.26 |
|---|---|
| 시계열 예측을 지도 학습으로 바꾸는 방법 - Time Series to Supervised Learning with Sliding window (1) | 2020.09.11 |
| Python Prophet - 자동차 판매량 시계열 데이터 예측하기(Time Series Forecasting) (3) | 2020.08.28 |
| XGBoost (4) - 머신러닝으로 부동산 가격 예측 실습하기 / Tutorial (0) | 2020.07.14 |
| XGBoost (3) - Python 가상 환경에 설치하기 (0) | 2020.07.13 |
| XGBoost (2) - Parameter 이해와 현업자의 설정 방법 (2) | 2020.07.09 |




댓글